
Screenplay Summarization Using Latent Narrative Structure
This is a blog post for our paper Screenplay Summarization Using Latent Narrative Structure accepted at ACL 2020.
We summarize episodes from the TV series “CSI: Crime Scene Investigation” by considering their screenplays and produce video summaries. According to cognitive analysis [1], in order to summarize a story it is necessary to access a high level analysis of the story that highlights its central concepts. Inspired by such cognitive studies and the screenwriting theory that provides a solid analysis of the narrative structure in movies and TV shows [5], we propose ways to incorporate knowledge about the narrative structure into general unsupervised and supervised extractive summarization algorithms.
You can find the CSI dataset used for summarization here, our pytorch source code here and our automatically created video summaries used for human evaluation purposes here.
Screenplay summarization as scene selection
Input: Screenplay as a sequence of $N$ scenes $s$.
Output: Sequence of $M$«$N$ scenes presenting the storyline; video summary of the selected scenes.
→
General extractive summarization algorithms
Previous work on automatic summarization is mostly focused on news summarization. When summarizing news articles, models can explicitly or implicitly take into account their simple structure: first few sentences reveal topic and key information; further details follow. In this domain, there are two popular extractive summarization approaches:
Unsupervised as a graph
TextRank[2] is a popular unsupervised summarization algorithm. For TextRank, we create a fully-connected graph $G=(V,E)$, where $V$ is the set of scenes in an episode and $E$ the set of interactions between scenes, i.e., semantic similarity. In a recent extension of TextRank[3], a directed neural version is proposed that considers neural representations as node features in $G$ and directed edges $E$ between scenes. In the directed neural $G$, we compute the centrality of each scene, i.e., how connected the scene is with the rest of the graph, as follows:
$\textit{centrality}(s_i) = \lambda_1 \sum_{j<i}e_{ij} + \lambda_2 \sum_{j>i}e_{ij}$
where $e_{ij}$ is the semantic similarity between two scenes $s_i,s_j$ and $\lambda_1,\lambda_2$ are the parameters that define the degree of influence from previous and future scenes in the screenplay. Finally, we select the top $M$ scenes that have the highest centralities as the summary.
Supervised as a sequence
Now we assume that the scenes belonging to the episode summary are given.
In a supervised scenario, we assume that binary labels denoting the scenes that belong to the summary. In this case, standard summarization models (e.g., SummaRuNNeR [4]) consider the input document as a sequence (in our case a sequence of scene representations), apply criteria such as:
content, i.e., contextualized scene representation
salience i.e., similarity with a global document representation
and train the network with cross-entropy loss.
Is general algorithms appropriate for summarizing episodes?
No!
Narratives (such as movies and TV shows) present a different and more complex structure. They deliver information piecemeal and the direction of the story changes multiple times as events unfold. Both cognitive analysis and screenwriting theory suggest that humans and automatic approaches alike should access a high level structure delineated by central events in order to understand, create or summarize a story.
Hence, we hypothesize that general summarization algorithms cannot be transferred directly from clean, straightforward articles to messy, complex and entangled stories, such as TV episodes.
Our solution: Incorporating narrative structure knowledge
How is narrative structure defined?
According to screenwriting theory [4], all films and TV shows independently of their genre have a common high-level structure. In order for a story to be compelling, certain key events, called turning points (TPs) should be present in specific points of the story. These key events further segment the story into meaningful semantic sections (i.e., acts).
There are several different schemes describing the narrative structure. Here, we use a modern variation that serves as practical guide for screenwriters. According to that scheme there are 5 turning points which segment the narrative into 6 thematic sections. We are mostly interested in the definition of the turning points:
TP1 Opportunity: Introductory event to the story occurring right after the presentation of the story setting and some background information about the protagonists.
TP2 Change of plans: Event where the main goal of the story is revealed. Thereafter the action begins to increase.
TP3 Point of no return: Event the pushes the protagonist(s) to fully commit to their goal; thereafter there is no return to pre-story state for them.
TP4 Major setback: The biggest obstacle for the protagonist(s); moment that everything falls apart (temporarily or permanently).
TP5 Climax: moment of resolution, final event of the story and the ‘‘biggest spoiler’’ in a film.
Previous work [5] demonstrated that such events can be identified in various Hollywood movies by both non-expert human annotators and automatic approaches.
Is narrative structure theory applicable to every story?
The definition of TP events that delineate the structure of a story is intuitive and it is shown that humans in general agree when attempting to identify such events in movies. However, we want to summarize CSI episodes which differ from movies in two ways:
They are episodes of a TV series instead of movies with isolated stories; there is some contuinity between the different episodes and a set of main characters appears in all episodes.
The episodes are specific to crime investigations and present a well-defined and discrete structure specific to crimes: finding the crime scene, identifying the victim, collecting evidence and concluding to the perpatrator.
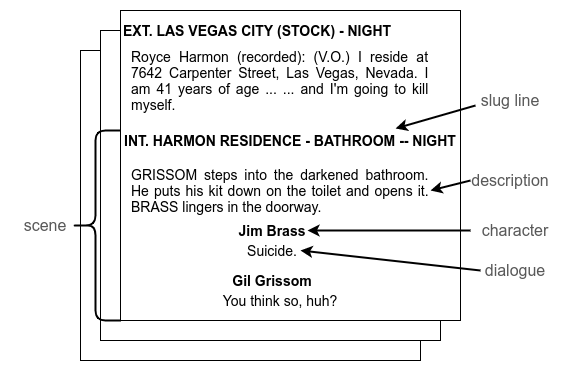
Let’s see whether we can manually identify the TP events based on the generic definitions provided by screenwriting theory in an actual CSI episode:
![]()
So, it seems that the narrative structure scheme can be applied to our dataset as well!
Automatic identification: Pre-training on TP identification
Another obstacle in incorporating knowledge about the narrative structure to our task (i.e., summarization on CSI episodes) is that we do not have structure-specific annotations or any other indication about the presence of TP events in the episodes. For this reason we use the TRIPOD dataset containing movie screenplays and annotated TP events in order to pre-train a TP identification network. We use the same architecture as in [5], but we simplify the network to only consider screenplay scenes –we exclude the plot synopsis information– and predict the scenes that act as TP events. For each of the five TPs, the network outputs a probability for each screenplay scene to represent the given event.
Summarization model: SUMMER
How can we incorporate the narrative structure into the general summarization algorithms?

Identification of TP scenes
Selection of scenes to include to the summary that are closely related to the storyline as identified by the TPs
Video summary by merging the videos of the selected scenes
Unsupervised as structure-aware TextRank
For each screenplay scene $s_i$ we compute a score $f_i$ that represents the probability that the scene represents any TP event. Then, we incorporate the structure-related scores in the centrality calculation of each scene as follows:
$\textit{centrality}(s_i) = \lambda_1 \sum_{j<i}(e_{ij} +$ $f_j$$) + \lambda_2 \sum_{j>i}(e_{ij} +$ $f_i$$)$
Intuitively:
The $f_j$ term in the first part of the equation (i.e., forward sum) increases increamentally the centrality scores assigned to scenes as the story moves on and we go to later sections of the narrative.
The $f_i$ term in the second part of the equation (i.e., backward sum) increases the scores of the scenes that are probable TP events.
Supervised via latent structure representations
Criteria for selecting summary scenes:
Content: Contextualized scene representations.
Salience: We introduce a new definition for salience. We explicitly measure the scene's similarity with the storyline of the episode, as identified in the latent space by the 5 TP events. Hence, in our case we use different vectors in order to represent different important plot points instead of assuming that there is one main topic that can be encoded into a single vector. Moreove, only a few scenes are identified as important and contribute to the representation of each key event.

Findings
Our experimental results demonstrate that knowledge about the narrative structure can boost the performance of both unsupervised and supervised methods. Interestingly, structure knowledge appears to be more important than character-related information (e.g., who is participating in the scene, what is the ratio of the main protagonists in the scene) that is traditionally used in the context of narratives. Human annotators also agree with our automatic evaluation and find our summaries more complete and informative.
However, we also investigate what is captured as ‘‘narrative structure’’ in the latent space by analyzing the TP-specific attention distributions. These distributions are close to few-hot vectors and hence we can observe the scenes identified as TP events. Here is an illustration of identified TP events for 4 episodes of the dataset:
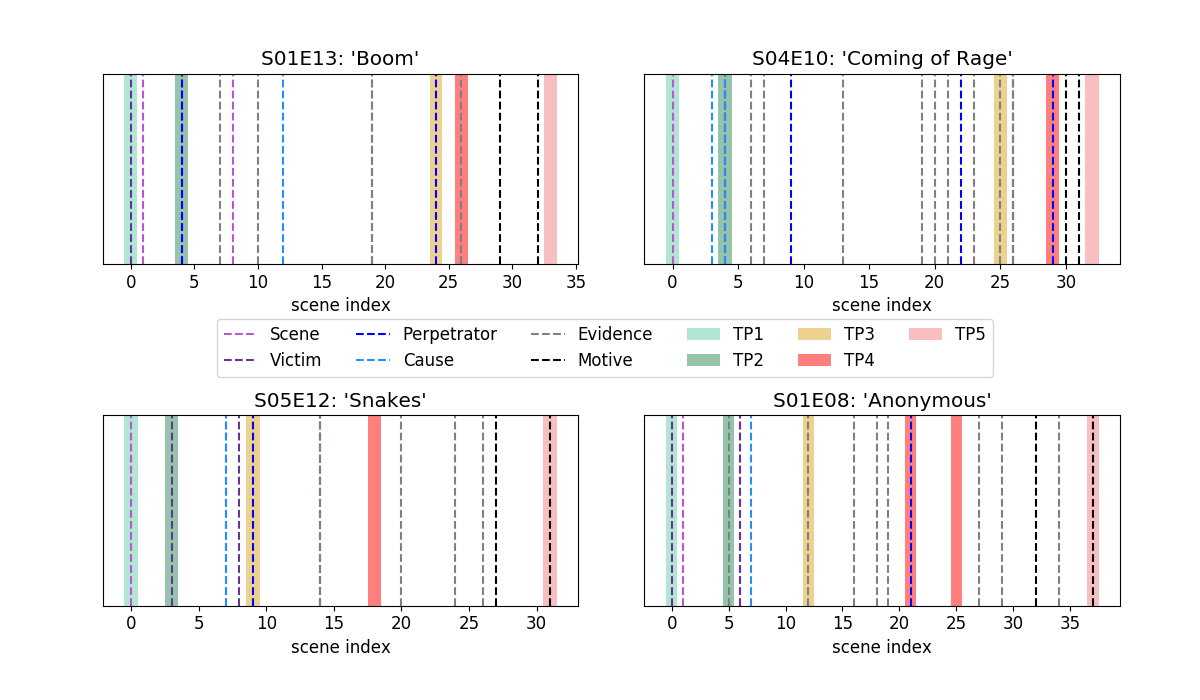
We emperically see that different TP events tend to capture information about different aspects of the summary. Moreover, we find that different TP events correlate with specific summary aspects:

Hence, we observe that the general definitions of TP events that can be applied to all kinds of narratives adopt a crime-specific definition in the case of CSI episodes.
Finally, during human evaluation we again find that SUMMER is able to cover more aspects producing more diverse and complete video summaries, since it selects scenes that directly address the latent identified aspects via the TP representations. Here are the actual video summaries produced by SUMMER and used for human evaluation.
As an example, let’s see the summary created by SUMMER for the episode ‘‘Swap Meet’’ (s05e05): 
References
[1] Lehnert, Wendy G. “Plot units and narrative summarization.” Cognitive science 5.4 (1981): 293-331.
[2] Mihalcea, Rada, and Paul Tarau. “Textrank: Bringing order into text.” Proceedings of the 2004 conference on empirical methods in natural language processing. 2004.
[3] Zheng, Hao, and Mirella Lapata. “Sentence Centrality Revisited for Unsupervised Summarization.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019.
[4] Nallapati, Ramesh, Feifei Zhai, and Bowen Zhou. “Summarunner: A recurrent neural network based sequence model for extractive summarization of documents.” Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[5] Michael Hauge. 2017.Storytelling Made Easy: Per-suade and Transform Your Audiences, Buyers, andClients – Simply, Quickly, and Profitably.IndieBooks International.
[6] Papalampidi, Pinelopi, Frank Keller, and Mirella Lapata. “Movie Plot Analysis via Turning Point Identification.” Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.